A "Narrated Noir"
"Footprints In Eternity" Narrated noir & music video by Mark DK Berry.
WORKFLOWS & PROJECT DETAILS
🎥 Description
A narrated noir: A man returns to London where he once worked as a mobster. Hoping to make a last play then get out for good.
-
Title Track Music: "Footprints In Eternity" by Mark DK Berry – Available on Bandcamp
-
Full Soundtrack: "Footprints In Eternity (Soundtrack)" by Mark DK Berry – Available on Bandcamp
-
Date Started: 9th April 2025
-
Date Published: 29th June 2025
🎬 About the Project
I consider these videos to be "proof of concept" and are a way to learn about AI movie making. We are 1 or 2 years away from being able to make a truly watchable short film with AI. This is just an example of "what could be done in May 2025 on a PC".
There's another frustrating truth with AI - no sooner than you learn a method it is out of date.
For this project, I decided to take on a bigger AI challenge than just a music video. I decided to try a "Narrated Noir". A narrated noir offered me several things:
- Narration to solve the dialogue issue (no convincing lipsync at the time)
- "Noir" can be pretty overdone and still be acceptable.
- Black and white, so I could avoid colour consistency issues (though some was done in colour).
- To get some experience in making a short film.
This gave me leeway to make mistakes. I didn't expect the end result to be done to a professional standard, but it was a way to learn the requirements of visual story-telling.
Doing a music score was new to me, so was creating "environment sounds" and narration in this context.
⚠️ Key Challenges
-
Time and energy. I let the script run to 10 minutes which in retrospect was foolish. 5 minutes would have been better, and I soon realised I was looking at about 90 days to complete it (it took 80). 120 video clips were used in the final cut.
-
Time issues were compounded by my hardware limitations.
-
When I finished the first run of video clips I hit my first problem - quality issues.
-
An example of the problem I ran into with quality on my rig:
- Shot name:
NN_10A_01G_served_1
- Prompt: "a man in trench coat and trilby hat throws an envelope of photographs onto a dining table in a restaurant. Camera slowly orbiting the table to the right staying focused on the group at the table and the man in the trench coat."
Example using VACE V2V to fix quality issues. Everything gets replaced while maintaining the scene structure.
-
Issue:
- Poor rendering quality, especially for groups at a distance:
- Faces appear smooth/plastic, features are distorted, eyes look off.
- objects moving can look distillated and fractured.
-
Attempts to solve:
- On day 40 I paused the project and took 7 days to test new models and workflows from the "TO LOOK AT" list.
- I also updated ComfyUI with latest patches.
- New stuff tested:
- Wan-fun
- CausVid
- VACE 14B
- VACE mask-edit swapouts
- ControlNet workflows
- V2V (video to video) workflows
- FFLF (First Frame Last Frame)
None resolved the issue of rendering quality for crowds/mid-distance faces on my current hardware. In the end V2V using VACE with controlnets did the best job for "middle distance" issues such as shown in the video above.
-
Limitations & Solutions:
- The quality issue was hardware limitation — my current setup couldn't scale to 720p effectively.
- I wanted to avoid renting server GPUs (e.g., 4090s via RunPod).
- I wanted to avoid online paid services:
- Most won't allow violent content anyway, and this scene was a segue to a restaurant fight.
-
Some things solved by updates - After taking 7 days out for testing, it wasnt a total loss. I had more tools to work with, but all of them added a cost of time and energy to the process. The question going into the second half was going to be - how much time was I willing to give each shot to getting the quality I wanted?
-
Pytorch 2.7 and CUDA 12.8 - during testing I ran into a couple of issues where some updated Comfyui workflows demanded I upgrade pytorch from 2.6 to 2.7, and CUDA from 12.6 to 12.8 for optimum speed. I was tempted, but knew this could cause other problems. So I parked that idea, but will upgrade for the next project.
-
😞 VEO3 and Flow released by Google - to add to the despondancy and frustration, Google released VEO 3 and Flow half way through my project. VEO 3 completely blew "open source" out of the water around the 22nd May 2025. It was impressive stuff. I took a couple of days off to sulk.
-
FFLF (First-frame-last-frame) is proving to be a winning approach. This is where you provide first image and last image, and the Wan 2.1 model makes all the frames in between. But it doesn't always go as planned (see video clip below). The solution is often simply finding a seed that has seen that kind of action in its training dataset, e.g. a steam train. Then it knows what to do with it. In the below video, it didn't.
First-Frame-Last-Frame - doesn't always go as planned.
-
Day 68. I finally completed 120, 5-second video clips to a standard that was okay. Not great, but okay. Now it was time to put them together in Davinci Resolve and start to work towards a final cut. I had some soundtrack ideas in place but it needed work. I also still had to create environmental sound ambience for the entire video, and the narration wasn't great, some parts needed redoing.
-
Lipsync tasks. I needed three shots with Lipsync. When I began the project, I'd hoped new methods would show up before I'd finished. Alas, no.
- The recommended open source version was considered to be LatentSync, but it led to OOM errors on my 12GB VRAM, and the author of the code seemed to think it was unfixable for low VRAM (5 months previously it worked for others, but updates had changed that).
- There was a new lipsync method (Multi-Talk) but it was in beta and would likely have OOM issues or could cause version problems on my Comfyui setup.
- So... I decided to use some free credits up on a subscription service rather than give up, or wait a month. I chose Hedra, which worked great for the first video clip, but then struggled with the second shot, and no amount of prompting persuaded it to use the woman for talking. Then it put me in a "30-minute wait-list or sign up". I wouldn't be signing up. I then ran out of credits.
- So I went to Kling next, where I had some free credits left over after testing it for the Kali video. I could pick the character to apply the lipsync audio, which was handy. So I did that. Though Kling didn't like my wav files, so I changed them to mp3 in Audacity.
Overall, I thought Hedra did a good job, but Kling was friendlier and I could pick characters. And that was the end of my brief flirtation with corporate AI. Hopefully "Multi-Talk" will be out on OSS and working on 12 GB VRAM before I start my next project.
By the end of this project, I had 30 different Comfyui workflows in my main folder, and maybe twice as many again that I'd trialled, tweaked, and discarded. I've shared the best ones here...
Right-Click and "Save link as" to download the ZIP containing Comfyui json workflows
-
The above zip file contains the following 18 json workflows for use in Comfyui that were used for this project:
-
Image Creation workflows:
- Flux text-to-image
- Flux daemon detailer
- Flux inpainting
- 360 degree 3D rotation from a single image
- ACE++ for face and object swapping using mask and controlnet
- Hunyuan3D create 3D model from front, side, back images
- Reactor face swap
- Style transfer/restyler with controlnet
-
Video Creation workflows:
- Wan 2.1 14B image-to-video (old workflow)
- Wan 2.1 14B FFLF (First-frame-last-frame)
- Wan 2.1 14B image-to-video (with Lora stack & Camera lora. Faster and newer workflow)
- Wan 2.1 1.3B polisher
- GIMM & RIFE Interpolation & Upscaler (to 1920 x 1080 @ 64fps)
-
Video Manipulation workflows:
- VACE 1.3B video masking and Lora character swap (swap anything out with prompt)
- VACE 14B V2V restyle using reference image and video for controlnet
- ReCammaster (1.3B) for adding camera motion to a video.
- Minimax remover 1.3B with SAM2 masking. (last minute inclusion)
-
Audio workflow
- MMaudio - audio based on video clips
-
I used standalone RVC for narration voice swapping, and the music I wrote myself rather than using AI tools.
-
One thing missing was a good removal tool for video. I either used the VACE 1.3B masking workflow and added reference image and masked then prompted the item away, or found work arounds. I never found a great solution for difficult item removals until the last days while editing, and have added it to the workflow zip file. The Minimax remover, but I only used it once so can't vouch for its ability, it seemed okay.
-
Versions I was running by the end of this project:
pytorch version: 2.6.0+cu126
Python version: 3.12.9 (tags/v3.12.9:fdb8142, Feb 4 2025, 15:27:58) [MSC v.1942 64 bit (AMD64)]
ComfyUI version: 0.3.40
ComfyUI frontend version: 1.21.7
All the above ran on my 3060 RTX GPU, but some of the workflows are now superceded by Comfyui improvements released in early June 2025. I recommend using the "Lora stack" items mentioned further down in the section on Loras Used & Trained. They came out after this project was close to finishing, but they will speed up render times and improve quality (I have added the workflow with them in to the zip file).
⏱️ Time & Energy Investment
-
Total KWhs on project: After 80 days I had used 150 KWhs of electricity. My 3060 RTX + PC draws about 250 to 300 watts when at peak use. I have slightly undervolted the card, hoping to avoid early burn out of the card and seen negligable impact on process times.
-
Comparisons to renting server: Assuming 200KWh to complete this project with <300 Watt draw on my PC + 3060 RTX GPU card (200 Watt max), I wondered how that might compare in cost to renting a 3090 GPU server, which is currently around US$ 0.22/hr, with possibly another US$8 per month for 100GB storage of comfyui setup with models.
- Ballpark cost: 200 KWh = 200,000 Watts of use. My 3060 card is max 200 Watt, a 3090 is max 450 Watts. Rental for 400 hours is US$88 not including diskspace. My home electricity cost is dependent on time of day, but assuming all peak-hour it comes to less than A$60 for 200 KWhs which is currently < US$40. But the 3060 and PC has an ownership cost to replace. If I was doing a project double the length (16 minutes playing time or more) then it might start to become worthwhile to look at renting a server. However, my calculations are based on the expensive side of what it's costing me to do it at home.
-
Midway through the project I took 7 days out for testing new stuff that had come out. This was necessary to try to find a solution to poor quality issues. I didn't solve the quality problem but found work arounds. I had a loose rule: 40 minutes max for video clip renders (I set this because I often have to rework video clips many times to get final results). With over 100 video clips, boundaries needed to be in place, else I'd still be working on this project in 2026.
-
It took 68 days to finish all the 5-second video clips to an average standard (about 120 made the final cut, many more did not). Some changes were required depending on how they worked in the visual story when put together. I then began work in Davcini Resolve to edit it together. I had finished the videos, but I still had to do the soundtrack, ambience FX, and fix-up any issues.
-
Day 74 - The first rough cut was finished. I had music, narration, sound FX, all the video clips in place and lipsync completed too. Now I just had to wait for the soundtrack copyright to pass through my distributors and then colourise the Final Cut before releasing it.
-
Day 80 - I finished the final cut.
💻 Hardware
-
GPU: RTX 3060 (12GB VRAM)
-
RAM: 32GB
-
OS: Windows 10
-
Lots of hard disk space: Two 8TB SATA for backup storage, and two 4TB drives for continually accessible media and relevant software just for this project. 500GB SSD drive for speed on C drive (Which is constantly filling up).
All projects are done on a regular home PC. I was definitely feeling the limitations on this project. It was doable, but not to 720p quality. 1024 x 576 was the max resolution I was able to achieve in time vrs quality (then use tricks to bump it up to 1920 x 1080 @ 64fps).
🧰 Software Stack
100% open source software (actually Davinci is not OSS, but is free)
-
ComfyUI (Flux, Wan 2.1, VACE, FFLF, inpainting models, Upscalers, Interpolation) I use the portable version.
-
RVC for narration voice training and swap of my voice.
-
Krita + ACLY plugin – Inpainting and upscaling base images. image editing tasks.
-
Reaper DAW – Storyboarding with shot names and timecode rendered to MP4. I also used it for Narration, Foley, and Music. Mixing levels before taking it to Davinci for Final Cut. Reaper gave me far more granular power on the audio mix and is good for basic video duties.
-
Audacity - general audio file management duties; chopping out silence, changing format from wav to mp3, etc...
-
Shotcut - great as a fast fix for individual video clips: Stabilising, cropping, editing, masking, mirroring, reversing, colour and light control.
-
Davinci Resolve 20 – Final cut and colour grade
-
LibreOffice – Tracking shot names, prompts, colour themes, fixes, takes, etc.
-
Notepad++ - with the markdown plugin. I use markdown for project tracking and cross-platform compatibility. (I use Kate for editing markdown in Linux. Markor and ReadEra on android phone)
-
Kopia for auto-backups on Windows.
-
Free File Sync for manual backups.
-
Syncthing for sharing data between computers and phones. This is useful for project development as an alternative to Dropbox but needs careful management, it works differently. (I left Dropbox due to their AI data sharing policy concerns)
-
Python - I use VSCode for python coding over-night batch runs of Comfyui API workflows. I used Eleventy & Tailwind to develop this website. (I recently migrated away from React and NextJS).
🎨 Loras Used & Trained
-
Training Wan 2.1 Loras on WSL2 (Ubuntu) with the "Wan 2.1 1.3B t2v 480" model:
- I finally got it working on my PC. So I made x3 Loras for the main characters: the hero, the female, and the villain. (I had to repeat train one when I messed up with the caption file names). These take me about 1 or 2 days to make the dataset images, then 4 hours to train. For info on Lora training see Loras. I don't feel skilled enough to post much on the process yet, but will in the future.
IMPORTANT NOTE: *I would try to avoid using famous faces to train Loras. Even though it is currently a grey area, futuristically it could lead to problems if you use other people's faces without constent. Future-proof your work by thinking ahead. And just as I finished the final set of videos, Disney sued Midjourney for copyright infringement around 12th June 2025.
-
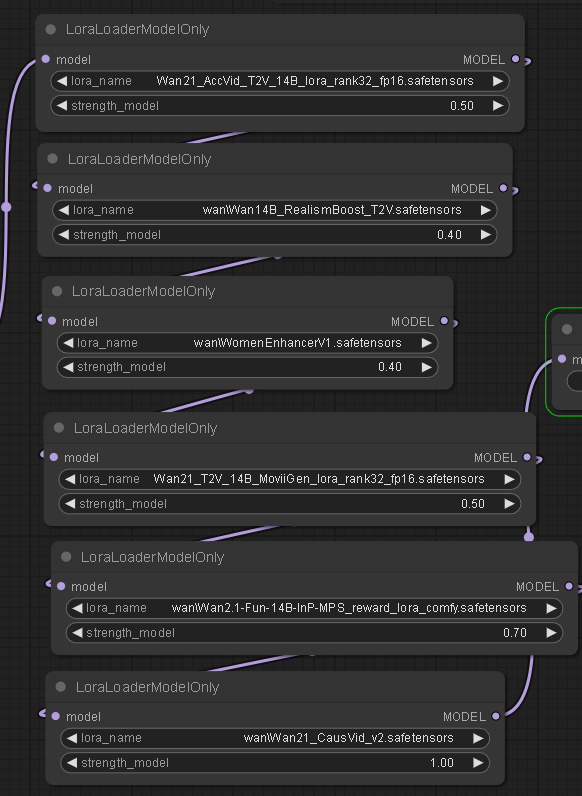
Lora stack example. I didn't use the below Loras during this project because most weren't available when I started. I will be using some of them, and others, during the next project. The image below is taken from a model called "Fusion X" that showed up in early June, but is a good example starting point. I highly recommend you use them. AccVideo and Causvid (or LightXv2 now) will speed up your workflows. I also recommend Self-Forcing model. All of these appeared in June and I am testing them now but they are incredibly powerful, and have brought my 3060 RTX back into the game. I can now do 720p where I could barely achieve it before.
- The below Loras can be downloaded from hugging face The realism one is named differently and can be downloaded from here. The "womenenhancer" I dont use, so don't know where that came from. (NOTE: everything evolves fast in this scene. The Causvid lora is now superceded by Lightx2v but settings need to be right in the workflow for either to work. )
📺 Resolution & Rendering Details
NOTE: A lot has been released in the last few weeks (early June 2025) that should improve quality and speed, but the below is what I started out with on this project.
NOTE: I was unable to achieve true 720p on this project using my hardware. As of now it is possible, which is fantastic and I will share all I learn in future workflows so follow my YT Channel to stay informed.
(NOTE: with the new improved things that came out in June, I can now do 1280 x 720.)
😵💫 Final Thoughts
-
I'd love to say I enjoyed it, but by day 40 with 720p video quality remaining out of reach on my hardware, it felt like a slog. I still had to write the soundtrack and figure out ambience sound FX, though the title track was finished. I knew the most challenging parts of the video work still lay ahead.
-
3 months is a long time for a project in AI. New things came out that I didn't risk trying, but worse was Google releasing VEO 3 and immediately my project became cheap and tacky in comparison. It was still only half finished. I continued on regardless, but it was demoralising to see people making movie-quality shorts in days on powerful servers, while I was on day 50 and had another month or more to go.
-
To give you an idea of how quickly things change, when I started this project (April 2025) I could get 832 x 480, 81 frames done to okay quality in 40 minutes if I was lucky. Using recently (June 2025) released tools and upgrades I can now achieve high quality at the same resolution in under 10 minutes.
-
I now know that I need to find a way to create repeatable sets and environments. I'll probably use Blender or Unreal Engine for it next time. This is the only way to get decent camera shots and angles, else I spend too long fighting AI trying to get it to do what I want, then fixing shots up after to make it look consistent.
-
Longer projects will definitely need well organised batch processing. There is also the question of whether it is cost effective to run long projects on a 3060 RTX with electricity costs, or to hire a powerful server GPU and run batch jobs at higher output quality.
-
Draw a line in the sand and know when to stop. There comes a moment where you have to say enough is enough. Draw a line in the sand and just accept that it's not going to meet the standards you set for it at the outset. I did this at day 68. It was time to finish the bloody thing and move on.
-
A second machine for parallel tasks like writing music would be good, but unfortunately I only have the one workhorse PC. While waiting for renders to finish I coded up this web site on my Linux lappy.
back to top