TIMELINE
“Creativity is intelligence having fun.” – Albert Einstein
Timeline of News in AI world and milestone events that changed the course of my AI movie making.
30th September 2025
Sora 2 released by OpenAI
It wasn't a big deal at first glance but then it became one. Briefly.
The reason was that it bridged a lot of problems OSS methods hadn't even started to address yet regarding movie-making capability. Not just in video, but in sound, dialogue, human interaction, consistency, prompt adherance, prompt "scripting", styling consistency, and speed of use to get good results.
By the time they shut off the initial launch of a free 100 daily limit, along with their unleashed do what you want with whoever you want launch approach (which probably generated thousands of IP Lawsuits), Sora 2 looked like the first truly capable movie-making LLM.
VEO 3 should have been, and it was a huge leap at the time, but people only ever produced short - and expensive - clips with it.
As soon as Sora 2 came out, people were making consistent, dialogue driven, perfectly stylised, startlingly accurate short movie content videos of 2 minutes or more in rapid fire. And the replication of people, shows, movies, even game scenarios, was undeniably good.
It was also undeniably stolen, i.e trained on stuff it should not have been trained on. OpenAI had done a daring and copyright-infringing thing here, and they were not even trying to pretend otherwise.
Legally their launch method was likely to generate a problem, it was done in such a way that it generated huge global buzz. But then within days of the launch, they quickly shut down IP and copyright useage, effectively killing off its value to public users immediately. Or so it seemed. It could have been a cunningly staged marketing ploy, because it achieved the following things:
-
Show the world they just made the best movie making model by far and let everyone use it for a few days "unlimited".
-
Then show the movie studios they can switch off IP copyright useage at will. This shows an option to charge and track use of IP, if they want it.
-
Now OpenAI is in a position to make deals with movie studios to control said IP, and if they don't... we'll they might turn the tap on again.
It was almost a warning - "If you dont go along with us, look what we can do."
If they'd priced Sora 2 well enough to challenge the cost of local OSS models and GPU + energy use, then OSS could have faced a bit of an exodus. But they didn't.
The thing that has happened here, and why I added it to the timeline, is that it is no longer about model competing with a model. Sora 2 achieved movie-making status by leaping over a number of obstacles in one go. Then three days after release they hobbled it for users, so for now it is business as usual in OSS.
28th July 2025
Wan 2.2 Dual Models released
Wan 2.2 High Noise + Low Noise Models
This marked the arrival of the first dual model workflow. Using Wan 2.2. High Noise model for the first steps to create the fundamentals of the video, and Wan 2.2 Low Noise model for the last steps to finalise the results.
This also marked the moment my 3060 RTX could not handle a workflow and fell over. At first. This then led me to work on the memory tricks I share in a video. You can find that in the Research page.
I got the models working together in the end, but I feel the Wan 2.2 model advantages cost too much in Time & Energy and require better GPU cards than mine. This is not to say I am missing out. I use the Wan 2.2 Low Noise model on its own quite a lot, especially with VACE. But I don't use the High Noise model at all.
Though it is said "the High Noise model is where the Wan 2.2 magic is" but I don't feel I am missing out. Time & Energy have the final say with 12GB VRAM cards, and I believe acceptable results are achieved with what I already have. This is not to say the Wan 2.2 might not provide higher quality results, just that I have not yet felt the need to use it as a dual-model workflow, since other workflows can achieve good results quicker.
This also marked a point in time where acceptable results were coming into focus. I did predict a levelling off moment at some point, and I think around September/October 2025 is going to start to see it. This is good news, because it will mean I can soon get on with a project.
The first realisation of this levelling of moment came for me when I found out that the public prefer movies at 24fps. I had been aiming for 120fps with "Footprints In Eternity" on the assumption that "it must be better". But it turns out not to be the case. This reminded me that everyone in the AI scene is shooting for the highest possible quality, while the public don't care. All they want is "good enough" story without visual distraction.
This is a very important and opens the door to AI film making. Once we can achieve human interaction, lipsync, emotive expression, and dialogue, along with "good enough" visuals, we can start to make movies in AI.
I believe this was the first moment that I reached that threshold in something, and it was frames-per-second. I no longer had to punch for 120fps or even 60fps. The public wants 24fps, and who am I to deny them that?
17th June 2025
Lightx2V Lora released (superceding CausVid Lora)
In the words of Kijai "[light lora] is proper distillation while causvid was more a hack we were using"
In both Loras the settings need to be right for it to work, but both of them speed up workflows considerably so are almost essential now to use one (and Lightx2v would be preferred).
Some notes to help you get it working:
"it doesn't have the issue the previous CausVid models had with the motion especially".
Recommended start-point settings: using 4 steps, lcm, 1 cfg, 8 shift. Works with vace, i2v, t2v, skyreels.
On using SLG with Lightx2v: Kijai — "that's kinda counterintuive though... SLG is CFG boosting technique and lightx2v is CFG distilled"
14th June 2025
MultiTalk released - lipsync using audio files to drive a reference image
Actually three useful models appeard around this time: Multitalk, InfiniteTalk, and FantasyPortrait
Together they put emotive lipsync into the Open Source arena in a way that looked realistic, and worked even with my lowly 3060 RTX. I only did brief tests in early July, then parked it while I worked on other things like Upscalers, and testing Character consistency models such as Phantom and Magref.
Multitalk was good, but soon gave way to InfiniteTalk, which was based on it and ran in the same workflow, but gave access to longer time frames. This also worked on 3060 RTX GPU. Kijai was still developing the code transition for it to his wrapper workflows at the end of August, and I began looking at it more seriously in early September.
In addition to that was Fantasy Portrait, this was special because it allowed taking a premade video from say a phone, and using it to drive the lipsync for the audio and the face expressions for the emotion. Again, I tested it only briefly, and as of posting this have not had a chance to test it further. I hold high hopes for InfiniteTalk and FantasyPortrait together solving most dialogue requirements.
13th June 2025
Self-Forcing and Fusion X models released
In the final stages of my "Footprints in Eternity" Noir project, two models got released that sped video generation up and improved quality considerably.
"Self-forcing" is a 1.3B text-2-video model but the speed and quality surpassed Causvid in many cases. A VACE version was also quickly created enabling reference images to drive the workflow, essentially making it image-to-video also. This workflow speeds up my 832 x 480, 81 frame workflow for i2v from 40 minutes low quality to under 5 minutes with high quality. There is some lack of prompt adherance and issues with background movement but the quality and speed is incredible. Further tests required.
"Fusion X" is a combined model of varying sorts (i2v, t2v, VACE) using Moviigen, AccVideo, Causvid, and some Loras burned into the model to improve cinematic quality, motion, and speed. I dismissed this model at first due to some negative commentary on reddit about it, but when I eventually tried it was mind-blown by the results. This brought higher quality with faster times. I went from 40 minutes at 832 x 480, 81 frames image-to-video models, down to under 10 minutes and much higher quality. (This was before updating my pytorch, sage attention, and CUDA to latest version, which would increase speed again.) A guy I spoke to was claiming 5 minutes on his 3060 hardware with all latest updates.
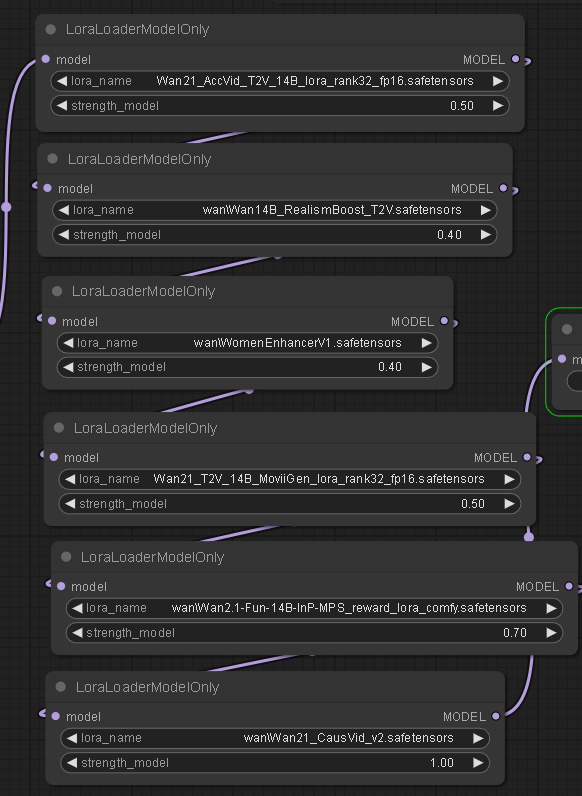
But it turns out "Fusion X" is just a bunch of Loras baked together with a Wan 2.1 model, and here they are, so it's probably better to use the Lora's on their own instead.
The below Loras can be downloaded from hugging face The realism one is named differently and can be downloaded from here. The "womenenhancer" I dont use, so don't know where that came from. (NOTE: everything evolves fast in this scene. The Causvid lora is now superceded by Lightx2v but settings need to be right in the workflow for either to work. )
12th June 2025
The Copyright Battle Begins in AI Movie Making World
Article - Disney sue Midjourney for AI copyright infringement
I expect the end result will be that small independants like myself get banned, or priced-out, from making movies using AI trained models, while the big studios will do deals behind the scenes to enable their use of it. Either way, this is just the start of it hitting the courts, and I expected it to happen after VEO 3 scared the industry.
The wild-card in all this is China. China make the best AI video models and currently gives them free to the open source community. This will be yet another reason why USA will want a war with China, as AI becomes the battleground in trade, business, and war, not just in movie-making.
But this marks the date the big guns came out swinging for AI in the movie-making industry. Midjourney was Disney's best bet for an easy win rather than the other big players that would be Google or Microsoft affiliated. What happens in this case will set a precedent for the future, so it is a story to watch as it unfolds. Could take years, though.
22nd May 2025
Google release VEO 3 and Flow which blows the AI movie making industry open
Not good news for me, but great for the AI movie making industry as they have achieved very realistic movie making ability, with excellent conversation abilities at all face angles, and it's super fast with amazing realism.
The entry price is US$230 a month, but people are already making incredible short stories in very quick time. You really can't tell some of it is AI.
This is depressing for me, because it sets the open source situation back a few months. What we are making now looks amateurish in comparison and takes a lot longer.
But as someone said, "corporate world is just a lagging indicator of where open source is headed".
I consider this a milestone because the paid competition just took a huge leap forward and that now becomes the gold standard to have to try to live up to. This is another reason long periods on a project suck. 5 days I can handle, 90 days I am already looking at obselete results.
But... the show must go on.
18th May 2025
CausVid Lora adapted by Kijai to speed up Wan2.1 workflows.
CausVid Lora available on Hugging Face
This Lora sped up the Wan 2.1 t2v and i2v models considerably. There was always going to be a cost to do so, but I was able to get 1024 x 592 image-to-video down from 40 minutes to 12 minutes (on a 3060 RTX graphics card), with the only impact being the prompts seemed a little less obedient. But for getting a first take at a decent resolution, this was a leap forward.
When testing seeds, I was able to get it down further to 5 minutes by reducing the steps in the KSampler, but importantly using the same resolution and seed number. This then sped up the testing phase while looking for good seeds that worked well. Something that previously cost a lot of time and energy.
31st March 2025.
VACE model released
The 1.3B model VACE was released that opened up the ability to mask and edit existing video clips. This allowed for swapping people or objects out. It was soon adapted to do restyling of videos, or allow for a low-denoise setting "polishing" of video clips to fix minor blemishes.
A by-product of this was that Wan 2.1 Lora training was now accessible to lower-spec machines such as my 3060 with 12GB VRAM. I was now able to train Wan t2V 1.3B models (as opposed to the larger 14B model) on Loras for characters that I could then use with VACE to replace the subjects in existing videos.
26th February, 2025
The image-to-video Wan 2.1 model was released
Article - Wan 2.1 model on comfy.org
This allowed more control over video creation by starting with an image and using a text prompt to drive the video.
Though the initial model required more VRAM than most people had available, by early March smaller models were developed from the base model that allowed those of us with 12 GB VRAM to run Wan 2.1 on our local machines.
The first video I was able to create was "The Name Of The Game Is Power" which can be seen below.
This video also included the use of a Lora trained on Flux (a text-to-image model) to add a character (in this case myself, the bearded chap) into the base image, which then would be used in the video clip by the Wan 2.1 model.
This worked well in this case, but if the character turned away from the camera or went behind something, the model would change the face. This is because it was starting with the image but had nothing telling it to maintain it. At this point it was not possible to train a Wan Lora (train a character to use in the video model itself) on a local PC.
5th December 2024
Hunyuan text-to-video model released by Tencent
Article - Tencent Release Hunyuan model
This was the launch date of the ability to make short video clips using text prompts that worked well. Example of this early model in action can be seen here in the video "Cafe". The workflow for it is available via the workflow page.